
Detección de diabetes. A partir de un dataset clínico de mujeres mayores a 21 años, determinar si alguien puede ser diagnosticada con Diabetes.
Embarazos: Número de Embarazos
Glucosa: Nivel de glucosa
Presión: Presión sanguínea (mm Hg)
EspesorPiel: Piel de triceps (mm)
Insulina: Nivel de insulina (mu U/ml)
IMC: Indice Masa Corporal (kg/m^2)
DiabetesFamiliar: Historia familiar de diabetes
Edad: Años
PacienteDiabético: Sí/No (1 / 0)
Descargamos el dataset:
if [ ! -f "diabetes_data.csv" ]; then
wget www.fragote.com/data/diabetes_data.csv
fi
ls -l
Funciones necesarias
# Funciones
import numpy as np
from sklearn.metrics import confusion_matrix
from sklearn.utils.multiclass import unique_labels
from sklearn.externals import joblib
import seaborn as sns
import matplotlib.pyplot as plt
def plot_confusion_matrix(y_true, y_pred,
normalize=False,
title=None):
"""
Esta función imprime y traza la matriz de confusión.
La normalización se puede aplicar configurando `normalize=True`.
"""
if not title:
if normalize:
title = 'Matriz de Confusión Normalizada'
else:
title = 'Matriz de Confusión sin Normalizar'
# Calculando la Matriz de Confusion
cm = confusion_matrix(y_true, y_pred)
# solo usar las etiquetas que se tienen en la data
classes = unique_labels(y_true, y_pred)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Matriz de Confusión Normalizada")
else:
print('Matriz de Confusión sin Normalizar')
print(cm)
fig, ax = plt.subplots()
im = ax.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
ax.figure.colorbar(im, ax=ax)
ax.grid(linewidth=.0)
# Queremos mostrar todos los puntos...
ax.set(xticks=np.arange(cm.shape[1]),
yticks=np.arange(cm.shape[0]),
# ... etiquetando la lista de datos
xticklabels=classes, yticklabels=classes,
title=title,
ylabel='True label',
xlabel='Predicted label')
# rotando las etiquedas de los puntos.
plt.setp(ax.get_xticklabels(), rotation=45, ha="right",rotation_mode="anchor")
# Loop over data dimensions and create text annotations.
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(j, i, format(cm[i, j], fmt),
ha="center", va="center",
color="white" if cm[i, j] > thresh else "black")
fig.tight_layout()
plt.show()
return ax
def saveFile(object_to_save, scaler_filename):
joblib.dump(object_to_save, scaler_filename)
def loadFile(scaler_filename):
return joblib.load(scaler_filename)
def plotHistogram(dataset_final):
dataset_final.hist(figsize=(20,14), edgecolor="black", bins=40)
plt.show()
def plotCorrelations(dataset_final):
fig, ax = plt.subplots(figsize=(10,8)) # size in inches
g = sns.heatmap(dataset_final.corr(), annot=True, cmap="YlGnBu", ax=ax)
g.set_yticklabels(g.get_yticklabels(), rotation = 0)
g.set_xticklabels(g.get_xticklabels(), rotation = 45)
fig.tight_layout()
plt.show()
Prepocesamiento de data:
# Importando librerías
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Importando Datasets
dataset_csv = pd.read_csv('diabetes_data.csv')
# Columnas de la data
print ("\nColumnas del DataSet: ")
print (dataset_csv.columns)
# Describir la data original
print ("\nDataset original:\n", dataset_csv.describe(include='all'))
# Revisamos los tipos de datos de las Columnas
print ("\nTipos de Columnas del Dataset: ")
print(dataset_csv.dtypes)
print ("\nDataset Total: ")
print("\n",dataset_csv.head())
dataset_columns = dataset_csv.columns
dataset_values = dataset_csv.values
Columnas del DataSet:
Index(['Embarazos', 'Glucosa', 'Presion', 'EspesorPiel', 'Insulina', 'IMC',
'DiabetesFamiliar', 'Edad', 'PacienteDiabetico'],
dtype='object')
Dataset original:
Embarazos Glucosa ... Edad PacienteDiabetico
count 768.000000 768.000000 ... 768.000000 768.000000
mean 3.845052 120.894531 ... 33.240885 0.348958
std 3.369578 31.972618 ... 11.760232 0.476951
min 0.000000 0.000000 ... 21.000000 0.000000
25% 1.000000 99.000000 ... 24.000000 0.000000
50% 3.000000 117.000000 ... 29.000000 0.000000
75% 6.000000 140.250000 ... 41.000000 1.000000
max 17.000000 199.000000 ... 81.000000 1.000000
[8 rows x 9 columns]
Tipos de Columnas del Dataset:
Embarazos int64
Glucosa int64
Presion int64
EspesorPiel int64
Insulina int64
IMC float64
DiabetesFamiliar float64
Edad int64
PacienteDiabetico int64
dtype: object
Dataset Total:
Embarazos Glucosa Presion ... DiabetesFamiliar Edad PacienteDiabetico
0 6 148 72 ... 0.627 50 1
1 1 85 66 ... 0.351 31 0
2 8 183 64 ... 0.672 32 1
3 1 89 66 ... 0.167 21 0
4 0 137 40 ... 2.288 33 1
[5 rows x 9 columns]Escalamiento/Normalización de Features
# Escalamiento/Normalización de Features (StandardScaler: (x-u)/s)
stdScaler = StandardScaler()
dataset_values[:,0:8] = stdScaler.fit_transform(dataset_values[:,0:8])
# Dataset final normalizado
dataset_final = pd.DataFrame(dataset_values,columns=dataset_columns, dtype=np.float64)
print ("\nDataset Final:")
print(dataset_final.describe(include='all'))
print("\n", dataset_final.head())
Dataset Final:
Embarazos Glucosa ... Edad PacienteDiabetico
count 7.680000e+02 7.680000e+02 ... 7.680000e+02 768.000000
mean 2.544261e-17 3.614007e-18 ... 1.857600e-16 0.348958
std 1.000652e+00 1.000652e+00 ... 1.000652e+00 0.476951
min -1.141852e+00 -3.783654e+00 ... -1.041549e+00 0.000000
25% -8.448851e-01 -6.852363e-01 ... -7.862862e-01 0.000000
50% -2.509521e-01 -1.218877e-01 ... -3.608474e-01 0.000000
75% 6.399473e-01 6.057709e-01 ... 6.602056e-01 1.000000
max 3.906578e+00 2.444478e+00 ... 4.063716e+00 1.000000
[8 rows x 9 columns]
Embarazos Glucosa Presion ... DiabetesFamiliar Edad PacienteDiabetico
0 0.639947 0.848324 0.149641 ... 0.468492 1.425995 1.0
1 -0.844885 -1.123396 -0.160546 ... -0.365061 -0.190672 0.0
2 1.233880 1.943724 -0.263941 ... 0.604397 -0.105584 1.0
3 -0.844885 -0.998208 -0.160546 ... -0.920763 -1.041549 0.0
4 -1.141852 0.504055 -1.504687 ... 5.484909 -0.020496 1.0
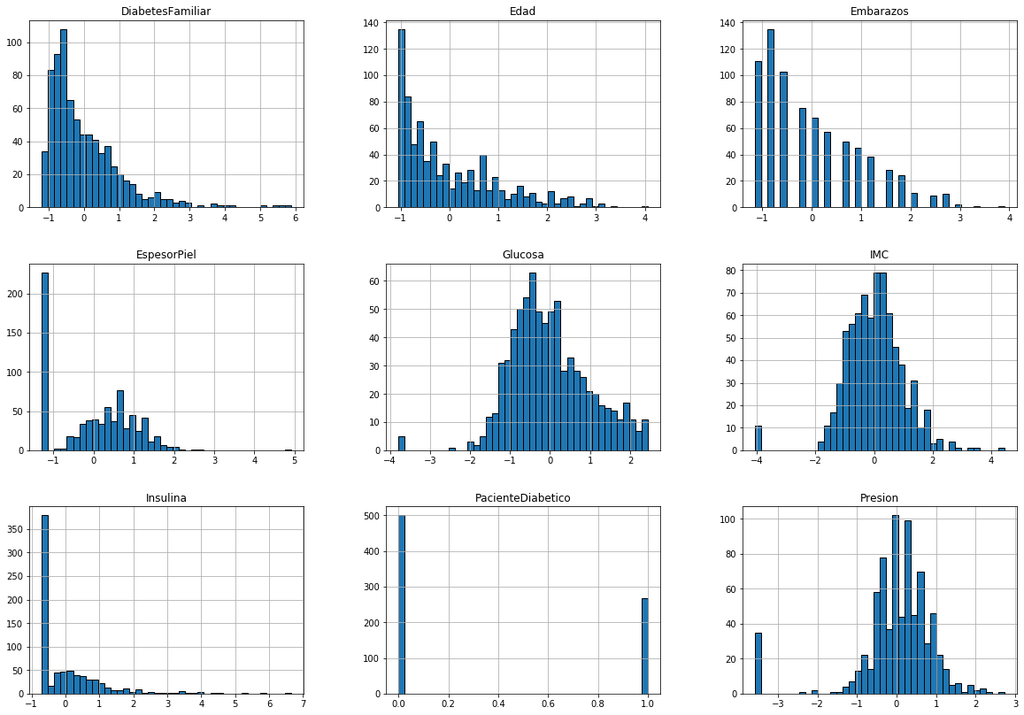
[5 rows x 9 columns]Revisamos los Datos Graficamente
# Distribuciones de la data y Correlaciones
print("\n Histogramas:")
plotHistogram(dataset_final)
print("\n Correlaciones:")
plotCorrelations(dataset_final)


Dividimos las columnas predictoras con el objetivo y 80%/20% para entrenamiento y pruebas, además generaremos una arquitectura de red neuronal:
Entrada => 8
Oculta => 5 / 3
Salida => 1
# Obteniendo valores a procesar
X = dataset_final.iloc[:, 0:8].values
y = dataset_final.iloc[:, 8].values
# Dividiendo el Dataset en sets de Training y Test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# Importando Keras y Tensorflow
from keras.models import Sequential
from keras.layers import Dense
from keras.initializers import RandomUniform
# Inicializando la Red Neuronal
neural_network = Sequential()
# kernel_initializer Define la forma como se asignará los Pesos iniciales Wi
initial_weights = RandomUniform(minval = -0.5, maxval = 0.5)
# Agregado la Capa de entrada y la primera capa oculta
# 10 Neuronas en la capa de entrada y 8 Neuronas en la primera capa oculta
neural_network.add(Dense(units = 5, kernel_initializer = initial_weights, activation = 'relu', input_dim = 8))
# Agregando capa oculta
neural_network.add(Dense(units = 3, kernel_initializer = initial_weights, activation = 'relu'))
# Agregando capa de salida
neural_network.add(Dense(units = 1, kernel_initializer = initial_weights, activation = 'sigmoid'))
# Imprimir Arquitectura de la Red
neural_network.summary()
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_18 (Dense) (None, 5) 45
_________________________________________________________________
dense_19 (Dense) (None, 3) 18
_________________________________________________________________
dense_20 (Dense) (None, 1) 4
=================================================================
Total params: 67
Trainable params: 67
Non-trainable params: 0
_________________________________________________________________Entrenando nuestro modelo con 100 épocas:
# Compilando la Red Neuronal
# optimizer: Algoritmo de optimización | binary_crossentropy = 2 Classes
# loss: error
neural_network.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
# Entrenamiento
neural_network.fit(X_train, y_train, batch_size = 32, epochs = 100)
Epoch 1/100
614/614 [==============================] - 0s 812us/step - loss: 0.6862 - acc: 0.5863
Epoch 2/100
614/614 [==============================] - 0s 125us/step - loss: 0.6793 - acc: 0.6401
Epoch 3/100
614/614 [==============================] - 0s 110us/step - loss: 0.6733 - acc: 0.6401
Epoch 4/100
614/614 [==============================] - 0s 112us/step - loss: 0.6678 - acc: 0.6401
Epoch 5/100
614/614 [==============================] - 0s 121us/step - loss: 0.6616 - acc: 0.6401
Epoch 6/100
614/614 [==============================] - 0s 123us/step - loss: 0.6549 - acc: 0.6417
Epoch 7/100
614/614 [==============================] - 0s 117us/step - loss: 0.6469 - acc: 0.6417
Epoch 8/100
614/614 [==============================] - 0s 113us/step - loss: 0.6398 - acc: 0.6417
Epoch 9/100
614/614 [==============================] - 0s 115us/step - loss: 0.6322 - acc: 0.6417
Epoch 10/100
614/614 [==============================] - 0s 122us/step - loss: 0.6248 - acc: 0.6433
Epoch 11/100
614/614 [==============================] - 0s 123us/step - loss: 0.6165 - acc: 0.6417
Epoch 12/100
614/614 [==============================] - 0s 116us/step - loss: 0.6080 - acc: 0.6547
Epoch 13/100
614/614 [==============================] - 0s 113us/step - loss: 0.5999 - acc: 0.6678
Epoch 14/100
614/614 [==============================] - 0s 119us/step - loss: 0.5908 - acc: 0.6792
Epoch 15/100
614/614 [==============================] - 0s 135us/step - loss: 0.5828 - acc: 0.6792
Epoch 16/100
614/614 [==============================] - 0s 113us/step - loss: 0.5751 - acc: 0.6873
Epoch 17/100
614/614 [==============================] - 0s 114us/step - loss: 0.5673 - acc: 0.6938
Epoch 18/100
614/614 [==============================] - 0s 117us/step - loss: 0.5595 - acc: 0.7020
Epoch 19/100
614/614 [==============================] - 0s 115us/step - loss: 0.5520 - acc: 0.7052
Epoch 20/100
614/614 [==============================] - 0s 107us/step - loss: 0.5445 - acc: 0.7182
Epoch 21/100
614/614 [==============================] - 0s 117us/step - loss: 0.5381 - acc: 0.7248
Epoch 22/100
614/614 [==============================] - 0s 110us/step - loss: 0.5322 - acc: 0.7264
Epoch 23/100
614/614 [==============================] - 0s 108us/step - loss: 0.5270 - acc: 0.7362
Epoch 24/100
614/614 [==============================] - 0s 122us/step - loss: 0.5217 - acc: 0.7394
Epoch 25/100
614/614 [==============================] - 0s 115us/step - loss: 0.5163 - acc: 0.7394
Epoch 26/100
614/614 [==============================] - 0s 118us/step - loss: 0.5117 - acc: 0.7459
Epoch 27/100
614/614 [==============================] - 0s 116us/step - loss: 0.5075 - acc: 0.7459
Epoch 28/100
614/614 [==============================] - 0s 109us/step - loss: 0.5050 - acc: 0.7476
Epoch 29/100
614/614 [==============================] - 0s 109us/step - loss: 0.5009 - acc: 0.7443
Epoch 30/100
614/614 [==============================] - 0s 122us/step - loss: 0.4984 - acc: 0.7459
Epoch 31/100
614/614 [==============================] - 0s 120us/step - loss: 0.4953 - acc: 0.7476
Epoch 32/100
614/614 [==============================] - 0s 118us/step - loss: 0.4930 - acc: 0.7508
Epoch 33/100
614/614 [==============================] - 0s 121us/step - loss: 0.4906 - acc: 0.7524
Epoch 34/100
614/614 [==============================] - 0s 108us/step - loss: 0.4886 - acc: 0.7492
Epoch 35/100
614/614 [==============================] - 0s 113us/step - loss: 0.4865 - acc: 0.7508
Epoch 36/100
614/614 [==============================] - 0s 111us/step - loss: 0.4850 - acc: 0.7541
Epoch 37/100
614/614 [==============================] - 0s 114us/step - loss: 0.4823 - acc: 0.7557
Epoch 38/100
614/614 [==============================] - 0s 116us/step - loss: 0.4808 - acc: 0.7590
Epoch 39/100
614/614 [==============================] - 0s 120us/step - loss: 0.4789 - acc: 0.7606
Epoch 40/100
614/614 [==============================] - 0s 112us/step - loss: 0.4775 - acc: 0.7622
Epoch 41/100
614/614 [==============================] - 0s 121us/step - loss: 0.4762 - acc: 0.7606
Epoch 42/100
614/614 [==============================] - 0s 129us/step - loss: 0.4749 - acc: 0.7622
Epoch 43/100
614/614 [==============================] - 0s 121us/step - loss: 0.4737 - acc: 0.7638
Epoch 44/100
614/614 [==============================] - 0s 128us/step - loss: 0.4726 - acc: 0.7655
Epoch 45/100
614/614 [==============================] - 0s 130us/step - loss: 0.4717 - acc: 0.7655
Epoch 46/100
614/614 [==============================] - 0s 116us/step - loss: 0.4706 - acc: 0.7704
Epoch 47/100
614/614 [==============================] - 0s 109us/step - loss: 0.4698 - acc: 0.7720
Epoch 48/100
614/614 [==============================] - 0s 110us/step - loss: 0.4688 - acc: 0.7720
Epoch 49/100
614/614 [==============================] - 0s 115us/step - loss: 0.4678 - acc: 0.7736
Epoch 50/100
614/614 [==============================] - 0s 114us/step - loss: 0.4673 - acc: 0.7736
Epoch 51/100
614/614 [==============================] - 0s 112us/step - loss: 0.4664 - acc: 0.7720
Epoch 52/100
614/614 [==============================] - 0s 121us/step - loss: 0.4658 - acc: 0.7720
Epoch 53/100
614/614 [==============================] - 0s 124us/step - loss: 0.4652 - acc: 0.7720
Epoch 54/100
614/614 [==============================] - 0s 112us/step - loss: 0.4646 - acc: 0.7720
Epoch 55/100
614/614 [==============================] - 0s 111us/step - loss: 0.4640 - acc: 0.7736
Epoch 56/100
614/614 [==============================] - 0s 112us/step - loss: 0.4634 - acc: 0.7704
Epoch 57/100
614/614 [==============================] - 0s 109us/step - loss: 0.4632 - acc: 0.7752
Epoch 58/100
614/614 [==============================] - 0s 130us/step - loss: 0.4626 - acc: 0.7736
Epoch 59/100
614/614 [==============================] - 0s 115us/step - loss: 0.4622 - acc: 0.7704
Epoch 60/100
614/614 [==============================] - 0s 119us/step - loss: 0.4617 - acc: 0.7720
Epoch 61/100
614/614 [==============================] - 0s 114us/step - loss: 0.4614 - acc: 0.7752
Epoch 62/100
614/614 [==============================] - 0s 108us/step - loss: 0.4614 - acc: 0.7736
Epoch 63/100
614/614 [==============================] - 0s 118us/step - loss: 0.4606 - acc: 0.7736
Epoch 64/100
614/614 [==============================] - 0s 115us/step - loss: 0.4602 - acc: 0.7687
Epoch 65/100
614/614 [==============================] - 0s 112us/step - loss: 0.4598 - acc: 0.7720
Epoch 66/100
614/614 [==============================] - 0s 116us/step - loss: 0.4595 - acc: 0.7687
Epoch 67/100
614/614 [==============================] - 0s 112us/step - loss: 0.4594 - acc: 0.7687
Epoch 68/100
614/614 [==============================] - 0s 121us/step - loss: 0.4587 - acc: 0.7687
Epoch 69/100
614/614 [==============================] - 0s 114us/step - loss: 0.4585 - acc: 0.7687
Epoch 70/100
614/614 [==============================] - 0s 110us/step - loss: 0.4578 - acc: 0.7671
Epoch 71/100
614/614 [==============================] - 0s 114us/step - loss: 0.4575 - acc: 0.7671
Epoch 72/100
614/614 [==============================] - 0s 125us/step - loss: 0.4572 - acc: 0.7687
Epoch 73/100
614/614 [==============================] - 0s 115us/step - loss: 0.4568 - acc: 0.7671
Epoch 74/100
614/614 [==============================] - 0s 107us/step - loss: 0.4564 - acc: 0.7671
Epoch 75/100
614/614 [==============================] - 0s 110us/step - loss: 0.4562 - acc: 0.7671
Epoch 76/100
614/614 [==============================] - 0s 111us/step - loss: 0.4558 - acc: 0.7671
Epoch 77/100
614/614 [==============================] - 0s 111us/step - loss: 0.4556 - acc: 0.7671
Epoch 78/100
614/614 [==============================] - 0s 110us/step - loss: 0.4553 - acc: 0.7671
Epoch 79/100
614/614 [==============================] - 0s 110us/step - loss: 0.4551 - acc: 0.7671
Epoch 80/100
614/614 [==============================] - 0s 115us/step - loss: 0.4547 - acc: 0.7671
Epoch 81/100
614/614 [==============================] - 0s 115us/step - loss: 0.4548 - acc: 0.7671
Epoch 82/100
614/614 [==============================] - 0s 111us/step - loss: 0.4547 - acc: 0.7671
Epoch 83/100
614/614 [==============================] - 0s 112us/step - loss: 0.4545 - acc: 0.7671
Epoch 84/100
614/614 [==============================] - 0s 110us/step - loss: 0.4538 - acc: 0.7671
Epoch 85/100
614/614 [==============================] - 0s 110us/step - loss: 0.4535 - acc: 0.7671
Epoch 86/100
614/614 [==============================] - 0s 113us/step - loss: 0.4534 - acc: 0.7671
Epoch 87/100
614/614 [==============================] - 0s 127us/step - loss: 0.4532 - acc: 0.7655
Epoch 88/100
614/614 [==============================] - 0s 127us/step - loss: 0.4527 - acc: 0.7671
Epoch 89/100
614/614 [==============================] - 0s 122us/step - loss: 0.4527 - acc: 0.7687
Epoch 90/100
614/614 [==============================] - 0s 112us/step - loss: 0.4523 - acc: 0.7687
Epoch 91/100
614/614 [==============================] - 0s 119us/step - loss: 0.4523 - acc: 0.7752
Epoch 92/100
614/614 [==============================] - 0s 112us/step - loss: 0.4522 - acc: 0.7736
Epoch 93/100
614/614 [==============================] - 0s 109us/step - loss: 0.4516 - acc: 0.7736
Epoch 94/100
614/614 [==============================] - 0s 116us/step - loss: 0.4513 - acc: 0.7752
Epoch 95/100
614/614 [==============================] - 0s 110us/step - loss: 0.4512 - acc: 0.7720
Epoch 96/100
614/614 [==============================] - 0s 114us/step - loss: 0.4513 - acc: 0.7704
Epoch 97/100
614/614 [==============================] - 0s 116us/step - loss: 0.4509 - acc: 0.7720
Epoch 98/100
614/614 [==============================] - 0s 117us/step - loss: 0.4510 - acc: 0.7736
Epoch 99/100
614/614 [==============================] - 0s 111us/step - loss: 0.4507 - acc: 0.7720
Epoch 100/100
614/614 [==============================] - 0s 110us/step - loss: 0.4505 - acc: 0.7720
<keras.callbacks.History at 0x7fd895218940>Predicción y Matriz de Confusión:
# Haciendo predicción de los resultados del Test
y_pred = neural_network.predict(X_test)
y_pred_norm = (y_pred > 0.5)
y_pred_norm = y_pred_norm.astype(int)
y_test = y_test.astype(int)
plot_confusion_matrix(y_test, y_pred_norm, normalize=False,title="Matriz de Confusión: Paciente Con Diabetes")
Matriz de Confusión sin Normalizar
[[94 13]
[17 30]]