
- Aprendizaje de Maquina (Machine Learning)

Es la capacidad de hacer actuar a las computadoras sin ser programadas específicamente, este es el primer gran paso para la Inteligencia Artificial, la inteligencia artificial trabaja con datos a quienes les aplican algoritmos y hace predicciones a partir de ellas.
Similaridad de Algoritmos
| Similaridad | Alg 1 | Alg 2 |
| Regresión | Regresion Logistica | Regresion Lineal |
| Arboles de Decision | CART | ID3 |
| Agrupamiento | Naive Bayes | Gaussian Naive Bayes |
| Redes Neuronales | Back Propagation | Redes Neuronales Convolucionales (CNN) |
- Tipos de Aprendizaje
Son 3 los tipos de aprendizaje mas populares:
#1 Aprendizaje Supervisado
Es un tipo de aprendizaje que utiliza un conjunto de data ya recolectada que contenga las entradas y las salidas (tambien conocidos como etiquetas u objetivo) de nuestra data de entrenamiento.
El objetivo de este algoritmo es describir la regla o conjunto de reglas que permite a la computadora recrear las salidas con nuevos datos de entrada.
Ejemplo: Podemos pensar en un conjunto de imágenes de perros y gatos ambos etiquetados correctamente respectivamente con el cual podemos entrenar un algoritmo que pueda predecir si una nueva imagen x mostrada es un perro o un gato. Para este caso las entradas serian las imágenes y las salidas las etiquetas…
#2 Aprendizaje No Supevisado
Para este tipo de aprendizaje tenemos solo las entradas pero no sabemos las salidas, lo que significa que el algoritmo debe buscar una estructura o patrones por el mismo.
Para el ejemplo anterior de las imágenes de perros y gatos, probablemente el algoritmo agrupe a los animales por tipo (perro/gato), o tamaño o peso o raza, etc.
#3 Aprendizaje SemiSupervisado
Esta es una mixtura de aprendizajes, entre Supervisado y NoSupervisado esto quiere decir que se le da al algoritmo un conjunto de datos con unos cuantos datos etiquetados y otros sin etiquetar, y a partir de los datos que ya están etiquetados el algoritmo debe encontrar patrones por si mismo para los siguientes datos.
Ejemplo: Imaginemos clasificar las paginas web de todo el mundo por nicho de mercado, etiquetar cada web es un trabajo super tedioso, es por ello que para esto se etiquetan solo algunas y a partir de ellas las ademas son etiquetadas a través de algoritmos predictivos.

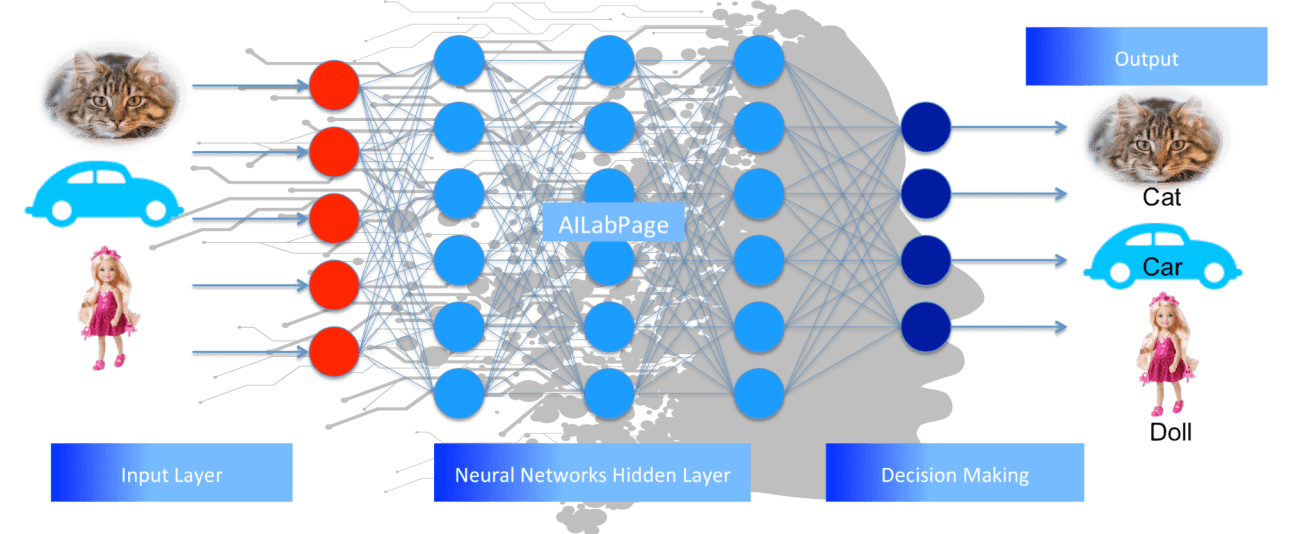
- Redes Neuronales
Tambien conocidas como Redes Neuronales Artificiales es un tipo de algoritmo de aprendizaje de maquina inspirado en las redes neuronales biológicas (cerebro biologico).
Es un algoritmo muy usado y el objetivo es resolver problemas de una forma similar a como el cerebro humano *creemos* que funciona.
Las redes neuronales con son parte de lo que es llamado Aprendizaje profundo (Deep Learning) que ha si probado para la solución de problemas complejos como reconocimiento de imágenes y procesamiento de lenguaje.

Estas son las 5 cosas que deberías saber sobre las redes Neuronales:
#1 Redes Neuronales son Especificas
Las redes neuronales son siempre construidas para resolver un problema específico.
Ejemplos:
– Predicción
– Forecasting
– Clasificación
– Reconocimiento de Patrones
#2 Partes de las Redes Neuronales
Las redes neuronales tienes 3 partes Básicas:
1. Capa de Entrada
2. Capa Oculta
3. Capa de Salida
#3 Formas de las Redes Neuronales
1. Feedforward:
De este modo las senales viajan en un solo sentido desde la entrada hasta la salida, un ejemplo de este tipo de RN son las Redes Neuronales Convolucionales (CNN o ConvNet) que son usadas para reconocimiento de imagenes.
2. Feedback (or Redes Neuronales Recurrentes, RNN):
Con este tipo de redes las senales viajan en ambos sentidos y pueden tener loops.
Este tipos de redes son mas poderosas y complejas que las CNN.
#4 Las Redes Neuronales son either fixed o adaptations
1. Fixed: Los pesos en una red fixed permanece estatica y no cambia
2. Adaptativas: Los pesos en una adaptativa no son estáticos y pueden cambiar.
#5 Las Redes Neuronales usan 3 tipos de datasets
– Dataset Entrenamiento: Se usa para ajustar los pesos de la Red Neuronal
– Dataset de Validacion: Es utilizado para minimizar el problema conocido como sobreentrenamiento.
– Dataset Prueba: Es usado para determinar cuan preciso la red nueonal ha sido entrenado.
La partition de la data para estos casos es usualmente 60/20/20.
Training Data: 60 %
Validation Data: 20 %
Testing Data: 20 %
